YOLO-World, introduced in the research paper “YOLO-World: Real-Time Open-Vocabulary Object Detection”, shows a significant advancement in the field of open-vocabulary object detection by demonstrating that lightweight detectors, such as those from the YOLO series, can achieve strong open-vocabulary performance. This is particularly noteworthy for real-world applications where efficiency and speed are crucial, like edge applications.
YOLO-World has grounding capabilities and can understand the context in a prompt to provide detections. You do not need to train the model on a particular class because the model has been trained using image-text pairs and grounded images. The model has learned how to take an arbitrary prompt – for example, “person wearing a white shirt” – and use that for detection.
YOLO-World exclusively supports object detection.
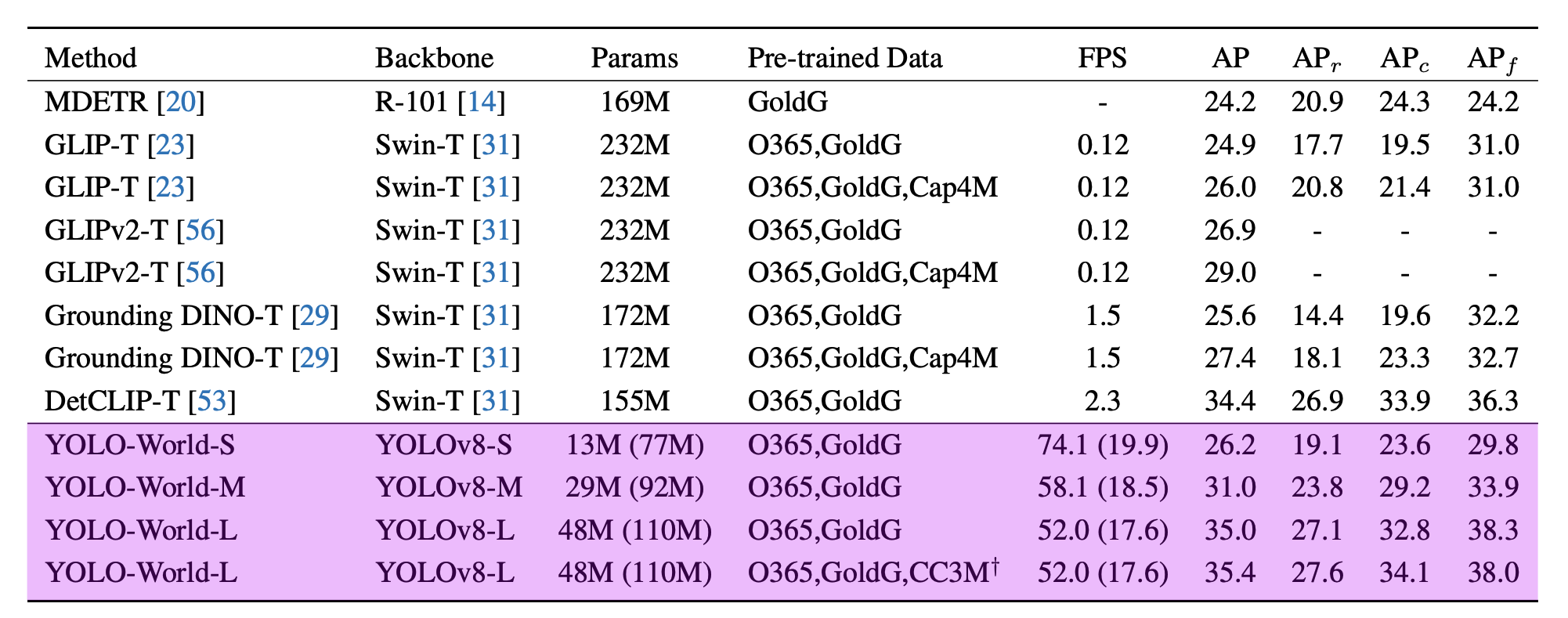
According to the paper YOLO-World reached between 35.4 AP with 52.0 FPS for the large version and 26.2 AP with 74.1 FPS for the small version. While the V100 is a powerful GPU, achieving such high FPS on any device is impressive.
First, install Inference:
Run the following command to set your API key in your coding environment:
export ROBOFLOW_API_KEY=<your api key>
Then, create a new Python file called app.py and add the following code:
