
Deploy CogVLM to Azure Virtual Machines
In this guide, we are going to show how to deploy a
CogVLM
model to
AWS
using Roboflow Inference. Inference is a high-performance inference server with which you can run a range of vision models, from YOLOv8 to CLIP to CogVLM.
To deploy a
CogVLM
model to
AWS
, we will:
1. Set up our computing environment
2. Download the Roboflow Inference Server
3. Try out our model on an example image
Let's get started!
In this guide, we are going to show how to deploy a
CogVLM
model to
AWS
using the Roboflow Inference Server. This SDK works with
CogVLM
models trained on both Roboflow and in custom training processes outside of Roboflow.
To deploy a
CogVLM
model to
AWS
, we will:
1. Train a model on (or upload a model to) Roboflow
2. Download the Roboflow Inference Server
3. Install the Python SDK to run inference on images
4. Try out the model on an example image
Let's get started!
If you want to upload your own model weights, first create a Roboflow account and create a new project. When you have created a new project, upload your project data, then generate a new dataset version. With that version ready, you can upload your model weights to Roboflow.
Download the Roboflow Python SDK:
Then, use the following script to upload your model weights:
You will need your project name, version, API key, and model weights. The following documentation shows how to retrieve your API key and project information:
- Retrieve your Roboflow project name and version
- Retrieve your API key
Change the path in the script above to the path where your model weights are stored.
When you have configured the script above, run the code to upload your weights to Roboflow.
Now you are ready to start deploying your model.
First, we need to create an AWS EC2 instance. EC2 is Amazon’s compute product that you can use to deploy virtual machines. Search for “EC2” in the search bar and navigate to EC2.
On the EC2 homepage, click the “Launch instance” button:
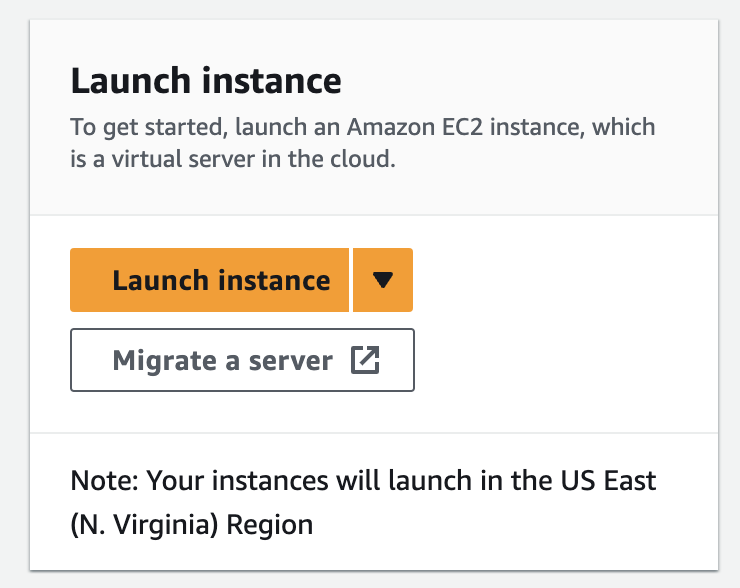
This button will take you to a page where you can configure the machine to create.
We recommend choosing the Amazon Linux operating system, which has been optimized for use in AWS. You will need to run Inference on a GPU device to run CogVLM. We recommend choosing a machine image optimized for deep learning, such as the Deep Learning Base GPU AMI image. This image will come with some tooling out of the box that will minimize GPU setup. If you want to deploy on a CPU device, the standard Amazon Linux operating system is recommended.

Once you have configured the virtual machine, you can deploy the system.
Next, sign in to your server with SSH. Read the AWS EC2 SSH instructions to learn more.
The Roboflow Inference Server allows you to deploy computer vision models to a range of devices, including
AWS
.
The Inference Server relies on Docker to run. If you don't already have Docker installed on the device(s) on which you want to run inference, install it by following the official Docker installation instructions.
Once you have Docker installed, run the following command to download the Roboflow Inference Server on your
AWS
.
Now you have the Roboflow Inference Server running, you can use your model on
AWS
.
The Roboflow Inference Server provides a HTTP API with a range of methods you can use to query your model and various popular models (i.e. SAM, CLIP). You can read more about all of the API methods available on the Roboflow Inference server in the Inference Server documentation.
The Roboflow Python SDK provides abstract convenience methods for interacting with the HTTP API. In this guide, we will use the Python SDK to run inference on a model. You can also query the HTTP API itself.
To install the Python SDK, run the following command:
Create a new Python file and add the following code:
This code will make a HTTP request to the /llm/cogvlm route on your Inference installation. This route accepts text and images which will be sent to CogVLM for processing. This route returns a JSON object with the text response from the model.
Above, replace:
1. ROBOFLOW_API_KEY with your Roboflow API key. Learn how to retrieve your Roboflow API key.
3. image.png with the image that you want to use to make a request.
4. prompt with the question you want to ask.
Let’s run the code on the following image of a forklift and ask the question “Is there a forklift close to a conveyor belt?”:

Here is an example output from the script above:
We take security seriously and have implemented comprehensive measures to keep your sensitive data safe
Below, you can find our guides on how to deploy
CogVLM
models to other devices.
The following resources are useful reference material for working with your model using Roboflow and the Roboflow Inference Server.
